Regular expression
Regular expression aka regex or regexp provides a concise and flexible means for matching string of text, such as particular characters, words or patterns of characters. A regular expression is written in a formal language that can be interpreted by regular expression processor.
- Really cleaver "wild card" expression for matching and parsing strings
- very powerful and quite cryptic
- fun once you understand them
- Regulars expression are a language unto themselves
- A language of "maker characters" - programming with characters
- It is kind of an "old school" language compact
Regular expression Quick guide
^ Matches the beginning of a line
$ Matches the end of the line
. Matches any character
\s Matches whitespace
\S Matches any non whitespace character
* Repeats a character zero or more times
*? Repeats a character zero or more times (non greedy)
+ Repeats a character one or more times
+? Repeats a character one or more times(non greedy)
[aeiou] Matches a single character in the listed set
[^XYZ] Matches a single character not in the listed set
[a-z0-9] set of character can include a range
( Indicates where string extraction is to start
) Indicates where string extraction is to end

The regular expression moduled
- before you can use regular expression in you program you must import library using "import re"
- you can use re.search() to see if a string matches a regular expression, similar to using find method for strings
- you can use re.findall() to extract portions of a string that match your regular expression, similar to a combinations of find() and slicing:var[5:10]
using re.search() like find
hand=open('file.txt')
for line in hand:
line = line.rstrip()
if line.find('From:')>=0:
print(line)
is same like
import re
hand = open('file.txt')
for line in hand:
line=line.rstrip()
if re.search('Form:',line(:
print(line)
using re.search() like startswith()
hand=open('file.txt')
for line in hand:
line=line.rstrip()
if line.startswith('From:'):
print(line)
is same like
import re
hand=open('file.txt')
for line in hand:
line = line.rstrip()
if re.search('^From:',line):
print(line)
we fine-tune what is matched by adding special characters to the string
Wild card characters
- The dot character matches any character
- if you add the asterisk character, the character is " any number of times"
^X>*:
line must start with Capital X and it may have any number of characters for by colon(:)
Matching and Extracting data
- re.search() return A True/False depending on weather the string matches the regular expression
- if we actually want the matching string to be extracted , we use re.findall()
[0-9] + one or more digit
import re
x= "my 2 facorite number are 19 and 42"
y= re.findall('[0-9]+',x)
print(y)
['2','19','42']

the repeat characters (* and +) push outward in both direction (greedy) to match the largest possible string
$F.+:

first character in the match is F following one or more characters and last character in the match is a:
Non Greedy Matching








- Builds on the top of IP(Internet Protocol)
- Assumes IP might lose some data stores and retransmits data if it seems to be lost
- handles "flow control" using a transmit window
- Provides a nice reliable pipe


Ports are similar to telephone number extensions



HyperText Transfer Protocol
- Since TCP and Python gives us a reliable socket what do we want to do with the socket? What problem do we want to solve?
- Application Protocols
- Main
- World wide web

The Hyper Text transfer Protocol is the set of rules to allow browsers to retrieve web documents from servers over the internet





Using Developer Console in browser
ASCII American standard code for Information interchange


Unicode means universal code





IN above program encode() converts into bytes
and decode() converts into normal form or data

Retrieving web page



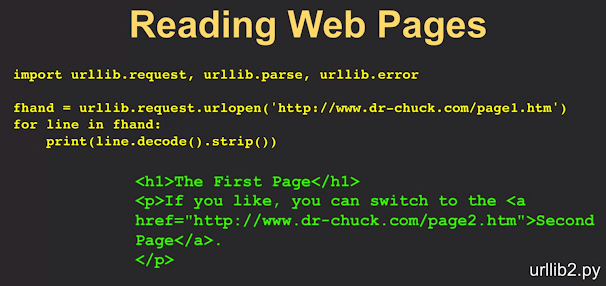


import urllib.request,urllib.parse, urllib.error
fhand=urllib.request.urlopen("www.somesite.come")
counts=dict()
for line in fhand:
words=line.decode().split()
for word in words:
counts[word]=counts.get(word,0)+1
print(counts)
What is web scraping ?
- When a program or script pretend to be a browser and retrieves web pages, looks at those web pages , extracts information and then looks at more web pages
- Search engines scraps web pages -we call this "spidering the web" or "web crawling"
Why scrap?
- Pull data particularly social data - who links to who?
- Get you own data back out of some system that has no "export capability"
- Monitor a site for new information
- Spider the web to make a database for a search engine



- The TCP/IP gives us pipes/sockets between application
- we designed application protocols to make use of these pipes
- Hypertext transfer Protocol (HTTP) is a simple yet powerful protocol
- Python has good support for sockets, HTTP and HTML parsing
If you want use our samples "as is", download our Python 3 version of BeautifulSoup4 from
Data on the web
- with the HTTP request/response well understood and well supported, there was a natural move toward exchanging data between programs using these protocols
- We needed to come up with an agreed way to represent data going between application and across network
- there are two commonly used formats: XML and JSON



XML (eXtensible Markup language)
XML become poluer when HTML become popular

- Primary purpose is to help information system share structure data
- it started as a simplified subset of the standard Generalized Markup language(SGML), and is designed to be relatively human-legible







XML schema
Describing a "contract" as to what is acceptable XML.









import xml.etree.ElementTree as ET
input = '''
<stuff>
<users>
<user x='2'>
<id>001</id>
<name>chuck</name>
</user>
<user x='7'>
<id>009</id>
<name>Brent</name>
</user>
</users>
</stuff>'''
stuff=ET.fromstring(input)
lst=stuff.findall('users/user')
print('User count:',len(lst))
for item in lst:
print('name:',item.find('name').text)
print('attr:',item.get('x'))
print('id',item.find('id').text)
Under standing REST Architecture is very important now a days
JavaScript Object Notation
discovered by Douglas Crockford
simply its object literal notation in JavaScript
simply its a light weight interchange format

Json represents data as nested "list" and "dictionaries"

output

Douglas Crockford - Discovered JSON
Service Oriented Approach
- Most non trivial web application use services
- They use service from other application
- credit chard charge
- Hotel Reservation system
- Service publish the "rule" application must follow to make use of the service(API)
Comments
Post a Comment